在互联网企业中,技术同学从大厂高 P 出来,空降到中小型的创业公司做技术管理的情况常有发生,这对于高 P 同学来说是一个较大的转变,会有一个适应期,有些比较顺利的渡过了这个适应期,也有些可能水土不服,甚至回流到大厂的情况。那么,作为一个高阶技术管理岗应该如何空降落地呢?如何在落地过程中保持平和的心态?如何快速上手业务,搞定事情?基于这些问题,我们有了这个落地实践指南。
高阶技术管理空降落地的关键点我觉得主要是两个大的方面,一个是心态,一个是节奏。
1. 心态
中国古代有一个”心态过门尤当先“的寓言笑话:
洞房花烛夜,羞羞答答的新娘低头看着地上,忽然掩口而笑,指着地上对新郎说:“看,看,看老鼠在吃你家大米。”
第二天,新娘早早起床洗漱,看到老鼠又在吃大米,大声怒喝:“该死的老鼠,竟敢偷吃我家大米!”
接着是“嗖”的一声,一只鞋飞了过去。
新郎听了大喜,知道新娘的心已经离开原来的娘家,过门到现在的这个家了。
过了门儿啦,新娘心态的转变从她对待老鼠的态度上就可见一斑,所以说,“心态过门尤当先”。
这个笑话对于我们新加入一个公司同样适用,心态很大程度上决定了是否能适应这个新的公司。 心态可分为 4 个点
1.1 对过往的态度:保持敬畏
在大厂工作多年,已经熟悉了大厂的流程和做事方式,习惯了有完善的制度和流程,习惯了强力的支撑系统。到新的公司,可能会觉得这里不行,那里也不好,甚至觉得自己是过来拯救团队的,是救世主。一上来就高谈阔论,方法论,高可用高性能等等,或者直接全部推翻重来,甚至会有直接换一个技术栈,这样操作往往会闹笑话,出问题,这里背后的原因是在于心态。有些急了,有些不切实际。
高 P 技术同学新入职一家新的公司,负责某块的技术,首先要有谦卑的心态。谦卑,就是对万事万物怀一颗敬畏之心,持一份包容情怀,谦卑的人更懂得尊重别人。
新的公司肯定是存在一些问题才会请你过来,所以有问题是一件很正常的事情,但是我们来了后,要保持谦卑,对原来的架构保持一颗敬畏之心,一个公司发展到这个规模,经历了非常多的风风雨雨,还能存活到现在肯定是有其道理的,而且还有一些从表面上看不到的问题,如冰山一样,深埋在水下,保持敬畏,尊重历史成绩。
1.2 快速融入的秘诀:不着急,不害怕,不要脸
“不着急,不害怕,不要脸”是冯唐在《冯唐成事心法》中常提的九字真言,对时间不着急,对结果不害怕,对别人的评价不要脸。
到新的公司,每一个新同学都会想想快速融入,想快点搞清楚公司的做事逻辑、业务流程,技术实现,想快点出成绩,想快点……
这些都是正常的,不要着急,给自己一些时间,给周围的同学一些时间,给事情的发生和发展足够的时间,遵从事物发展的客观规律,尽心尽力,有定力和耐心,在理解公司战略的基础上,沉下去把业务做起来,不用害怕,一切都会是最好的安排。
不要脸,是指快速融入现有团队不要脸,多听听大家的意见,为大家争取一些小的利益,和大家一起吃饭,一起加班,一起讨论问题,有空出去多聚餐,喝点酒,喝多了才好称兄道弟。
同时,放下过去的种种,不管你在过去是什么岗位,带多大的团队,不管是 CTO 还是技术总监,这都是过去的平台给你的,都已经是过去式,在新的地方你就是一个萌新,最多算一个工作很多年的老萌新,作为一个萌新就是要多看,多问,多想,不要脸的那种。
多看看公司的文档,虽然文档刚开始不那么全,但是只字片纸也能让我们对业务有更多的了解;多看看同事的做事方式和流程,知道在这样一个新团队里面大家的工作方式和节奏,发现好的地方和不好的地方,先记下来;多问问公司呆的久的人,有问题的时候多问问业务线的负责人,寻根究底的把项目搞清楚;多想想一个项目或一个团队是放在那里,多想想一个人为什么会出现在某个项目,多想想自己是来做什么的,多想想自己能带来什么价值。
在融入的过程中,不要怕丢脸,敢于被打脸,你问问题的人可能年龄比你小,工作年限比你少或者各方面都不如你,但是在这项目就是比你熟悉;或者一个完全陌生的人,很慢才回你的问题,甚至不回,这些都不重要,关键点是能得到你要的信息,能够帮助你更多的了解公司或项目。在公司的会议上敢于发表自己的意见,可能是错的,可能会被打脸,这些都不重要,关键点是能让更多的人认识你,更快速的融入新的公司。
如此,不着急,不害怕,不要脸,快速融入。
1.3 应有的工作态度:尽心
是尽心,而不是尽力,因为尽心和尽力是两回事。尽心做事和尽力做事,有天壤之别。
其差别关键点在于投入度,如果有人问有没有把握把事情做好,回答是尽力而为,这个回答没有错,也显得很敬业,但是其潜台词通常是“我的能力只有这么多,所以就只能做这么多”,但是每个人的潜力都是很大的,个人的力量可以释放得更充分一些。
如果是尽力,其潜台词是“我一定能完成任务,而且能做得更好、更多”。尽力有些给自我设限,只对自己的能力负责,缺少一些进取之心,只有尽心才能释放潜能。在选择团队成员的时候,一个尽心的员工,哪怕能力差一些,技术差一些,进展慢一些,但是投入度高,能全心全意的投入来完成工作,非常积极,假以时日,能力,技术、进度都将不会是问题。假设一个人的能力值是 1 ,一个尽力的人最多只愿意发挥 1 的能力值,甚至 0.8 ,而对于一个尽心的人来说,哪怕自己的能力值没有 1 ,其也会想办法达到 1 ,甚至超过。不给自己设限,释放自己的潜能。
尽心能带来安全感。尽心做事的时候会有特别重的 Owner 感,有那种这个事情就是我的,和其它东西无关,纯粹是想把这个事情做好;我的心血,我做的东西都在上面,就有了极强的安全感。 这里还有一个前置逻辑,就是信任,组织对个人的信任,组织认为这是你的事情。
1.4 能成事的做事方式:躬身入局
罗胖在 2019 年的跨年演讲中提到了一个概念–躬身入局,是曾国藩讲的一个故事,让人印象至深。 故事是这样的:
两个农人,挑着沉重的担子,相遇在农田间狭窄的田埂上。
他们谁也不愿意相让,因为那样的话,想让的那人就要一脚踩到泥泞的水田里,沾一脚泥。他们就那样顶上了,谁也不让谁。
作为一个旁观者的你该如何相劝呢?
我们能想到的是:退让一步,海阔天空,要不都走不了。
其实大多数人,有时候脑子里想的就是:“我凭什么要让你?大不了都不走,看谁犟得过谁!”
曾老先生从另一个角度提出了解决问题的方法——做一个躬身入局的人:
旁观者跳入水田,接过其中一个人的担子,让他先过。这样,问题就解决啦。
这也就是曾老先生所说的:”所谓天下事,在局外呐喊议论总是无益,必须躬身入局,挺膺负责,方有成事之可翼。“
何为做事之人?
不是置身事外,指点江山。而是躬身入局,把自己放进去,把自己变成解决问题的那个人。
躬身入局是对一个管理者基本的要求,是对其执行力的要求。真正的执行力是深入业务场景,和产品,运营、开发小伙伴在一起,共同解决问题、共同克服困难、共同面对挑战、共同承担责任。败则拼死相救、胜则举杯同庆。时时刻刻思考“自己在团队发展过程中扮演什么角色”这个核心问题,以及如何把深度思考后的结论付诸行动,持续迭代。
清晰了心态,我们再聊一下入局的节奏。
2. 入局节奏
人生犹如棋局,职场更甚。能识局者生,善破局者存,掌全局者赢。
2.1. 识局
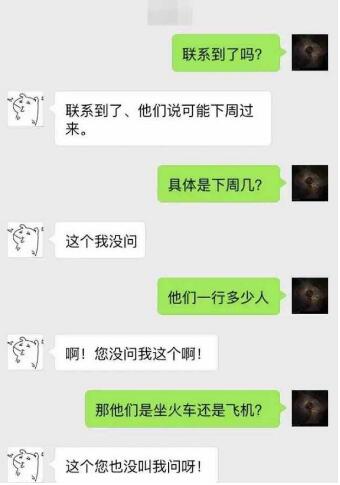
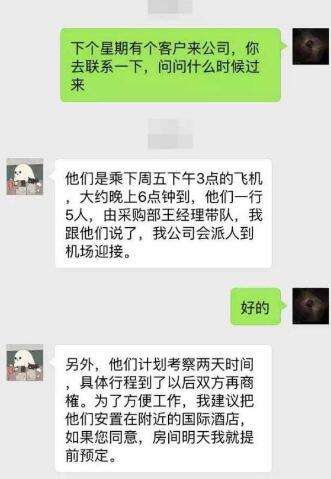
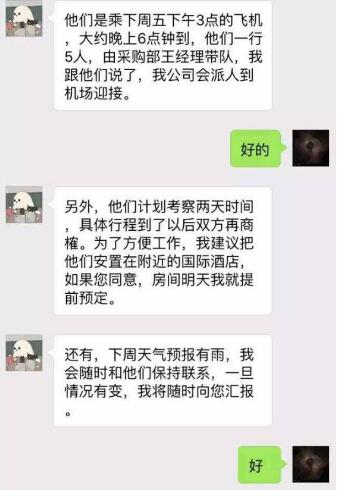
- 了解行业大背景,公司所在的赛道是什么?如果是创业公司,投资人是否关注这个赛道?主要营收靠什么?竞争对手有些?竞争对手的生存情况如何?这个步骤应该是面试这家公司之前就做了一些,本次就是细化其中的更多的关键数据,为后续的一些判断和决策提供顶层的支撑。
- 了解公司大背景:公司的文化是什么?大家是如何协同工作的?时间管理是怎样的?做事的价值观是怎样的?怎样的人在公司会更能得到大家的认同?
- 了解所在位置: 所负责的业务在公司的位置在哪?所负责的团队在公司的位置在哪?对接的部门,合作的人是哪些?有哪些诉求?业务边界在哪里?利益的边界在哪里?公司大的项目有哪些,干系人有哪些?项目历史情况,现在的情况如何等等;
- 了解团队成员:逐一和团队成员做一次 1v1,了解其背景,从 HR 处拿到入职时间 / 工作年限 / 级别 / 薪资结构等信息,了解人才梯队
- 了解现在的问题有哪些?挑战点有哪些,是人的问题,流程的问题,还是历史的问题等等,了解清楚公司招我过来是希望我解决什么问题的。
2.2. 破局
2.2.1 先小后大,以点破面
新官上任不用着急,先梳理业务逻辑,人才梯队,业务流程等等,找到问题点,找到破局点。
不要图大而全,不要一上来就搞大系统,先做小,从小点突破,拿到业绩和成果,建立信任,然后再做大的规划。 大的规划从规划到落地需要的时间太长,这样一个很长的时间里面如果没有产出,没有看到有成效的内容出现,可能还没有等到开始落地就已经出局了。 做小点是为了解决生存问题,做大的规划是为了解决发展的问题,顺序不能搞反了。
常见技术破局点:某些服务的性能问题,频发的告警服务,高负载的数据库,客诉问题多的点,新项目的技术架构方案,研发流程中的卡点,构建发布流程的优化,长期没有人能解决的问题、痛点或难点并且能快速解决的。
2.2.2 搭班子,带队伍
除了专注于破局的点和事项以外,尽快搞定人的问题,把团队搭起来,把人才梯队搭建好,管理者更多的是通过一线同学的手来拿结果,没有一个合格的团队,破局难,掌局更难。
首先,做好现有团队的沟通工作,不要让人觉得你是来抢事的,要让他们相信你是来帮忙的,来帮大家解决问题的,空降后和团队在行政上是上下级关系,但是根本上是合作的关系,来的作用是帮忙大家的。带领大家一起赢,遇到问题,是跟我上,而不是给我上。
其次,尽量用现有团队成员,也可适当新招或带一些人过去。现有团队有其优点,也会有其缺点,这些人在公司的时间长,掌握的信息量和资源都是一个新人缺失的,甚至有的人是跟了老板多年的老员工,能在老板面前说上话,甚至可能老板会问新来的这家伙感觉怎么样。在刚到团队的时候,要团结这些原有团队的人,有助于快速掌握资源和信息,加速你融入和破局的过程。
最后,在团队中找到志同道合的人,作为核心成员培养他们,让他们成为你的得力助手。饼还是要画的,落到手的实际也是需要有的,大棒和枣一个都不能少。
如果现有团队里面有不服你的人,极度不配合,但是还是要想办法去融入,不要脸的那种,等站稳后再看怎么处理。比如有一个 leader 不服,到处鼓动大家不配合工作,没关系,继续安排工作,只要工作能完成得好就行,而且还给比较好的绩效,针对好的绩效再提出高的标准,如果没有达到标准再降绩效,同时,招聘或内部提拔一个可以替代的同学,半年或者一年以后,站稳了后再视情况考虑后续的操作。

凡事都有套路,还是套路得人心,常用管理套路:
沟通反馈:1v1、个人目标制定、OKR、反馈、周报、周会、月会、团队建设、非正式沟通、向上管理
项目管理:项目进度、风险管理、紧急需求、复盘、跟进、反馈、拿结果
项目质量:线上稳定性、代码质量、Code Review、交付质量
人员管理:备份、淘汰、晋升、激励、绩效管理,360
人员招聘:业务盘点、人才盘点、人才素质模型、人才梯队、实习、试用
学习:总结、分享、交流、达摩院
2.2.3 破局
在和团队充分沟通,了解一些业务,了解业务中的痛点后,根据难易程度和优先级,选择个人觉得有挑战,好突破的点,找到破局点后,和领导沟通,得到充分的支持和授权,拉兄弟们一起干,和团队一起拿结果,在这些小点的累积中,上级对你的信任、团队对你的信任慢慢就建立起来了,如此,在这个新环境算是存活下来了,至此,已破局。
2.3 掌局
破局以后,随着时间的增加,从一个新人慢慢变成老人,对业务越来越熟悉,对人也越来越熟悉,此时不能飘,得躬身入局,把自己放进去,把自己变成那个解决问题,能掌控全局的人。
掌控全局可以从人员管理、团队演进和流程机制三个方面来掌控。
2.3.1 人员管理
人员管理主要是人的聘用育留。
- 招人:招人得先有业务,研发是为业务服务的,先搞清楚业务是要做啥,然后才是盘人,看看现在有什么人,都有什么样的人,还需要什么样的人,这样的人在哪里可以找到,以及给这些人我们可以提供什么样的待遇,什么样的机会等等;常用套路:业务盘点,人才盘点,人才画像,人才素质模型,人才地图,面试流程,面试官标准,人才策略,内推,专场,
- 用人:一线执行的同学看才能,对于技术同学来说就是技术水平怎么样,另外,还会看态度,或者说是工作的投入度,对于投入度高的同学会有一些资源倾斜;中层看德行和才能,这里的中层是指有管理职能的同学,同样也需要看技术能力,同时要看规划的能力,项目管理能力,沟通能力等等;高层看格局,是不是能从让公司更好出发来解决问题,而不是局限于自己的一亩三分地;常用套路:聚集,复盘,人才梯队,人才密度,分层用人,360度考核,加减分制,模块负责人,需求负责人,项目管理,风险管理,老人做新业务,新人做老业务
- 育人:这块主要是培训分享,新人融入,以老带新,员工成长,常用套路:IDP,导师制,分享会,管理培训,技术通道,自我迭代,培训体系,职级体系,文化,价值观,方法论,系统化
- 留人:基层基本上是看待遇,这里的待遇除了薪水,还看一些软性的福利和团队氛围,说白了就是看呆得爽不爽,有没有成就感,有没有感受到成长;中层靠情感,主要是领导是不是靠谱的领导,能不能帮助他提升,是不是一起奋斗过,对团队有感情了就不那么容易走;高层就要看事业了,主要是看这个事情是不是能做得大,大家在一起最后会不会把这个蛋糕做得更大,能让自己有那种事业的成就感,并且在事业中能得到较大的回报。
2.3.2 团队演进和价值观
对于一个团队来说,一般分为三个级别,初级,中级,高级,但是这三个级别并不是泾渭分明的,可能会三个级别的东西会同时存在,因为团队中包含的内容模块较多,不同的内容模块所在的级别不一样。
- 初级团队:初级团队靠骨干,以人治为主,这个阶段把核心骨干找到或者培养起来,让他们来搞定事情;
- 中级团队:中级团队靠规范,以人治 + 流程规范为主,在核心骨干的基础上,把好的经验以流程规范的方式沉淀下来,就算是核心骨干走了,还有东西可以传承;
- 高级团队:高级团队靠系统,把好的规范做成系统,用系统来驱动团队的进步,在系统的支撑下,让好的东西传承下来,让大家更高效更好的工作。
三个层面团队不是一蹴而就的,也没有清晰的分层,是一个演化的过程,从培养骨干开始,到规范化,到系统化落地,一点点积累,这样整个团队就会变得更好一些。这也是带研发团队最大的挑战。
在清晰了解团队所在阶段的同时,团队领导者需要从平时的工作中提炼出适合自己团队的价值观。
价值观是什么?
团队的价值观就是表达一个团队赞同什么,反对什么,是一个团队做事的行为准则。 价值观会潜移默化地体现在团队成员的做事的态度和方式方法上。
如我们的价值观是:
- 允许犯错,但不容忍罔顾教训、一错再错 这个是《原则》这本书里面提到一个观点,也是我们非常认可的一个观点,允许犯错是让大家不要畏惧挑战,敢于试错,不容忍罔顾教训是我们遇到问题和错误要复盘和总结,找到问题的根本原因,总结出方法论,后续可以规避类似的错误。
- 长期有耐心,基于深度思考的持续迭代 长期有耐心是一本讲美团的书里讲的内容,对于我们同样适用,持续迭代,长期有耐心的把业务做好,提升自己,自我迭代。
2.3.3 机制和系统化建设
带研发团队,在流程机制方面主要是关注研发效率和研发质量。对于研发效率和质量需要有一个完整的研发流程来保证,一般的流程如下:
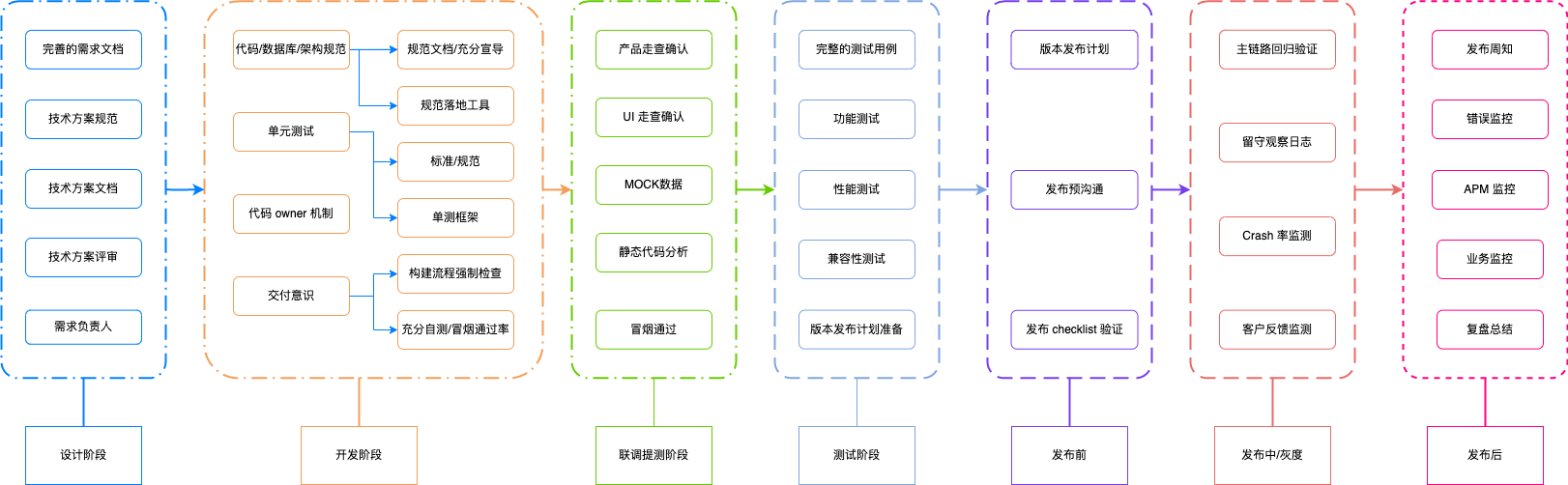
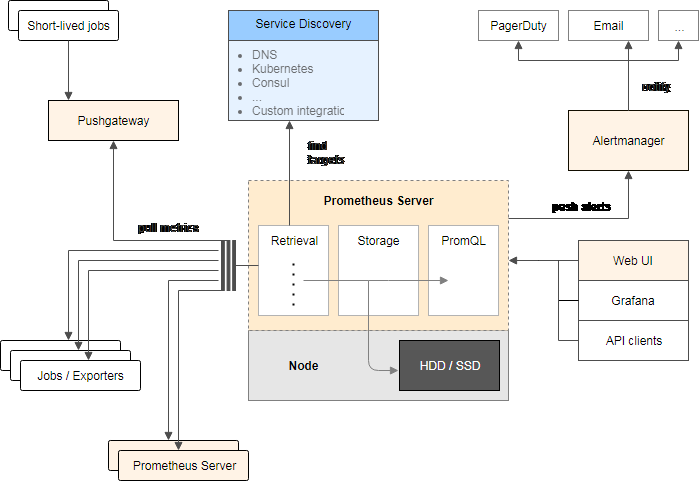
流程保障之外,还需要和产品,UI 等各方确认协同的节奏,如周需求评审机制,双周 APP 版本发布,版本回顾会等等。 同时我们需要制定团队的标准和规划,并且在过程中根据需要迭代这些标准规范,常见标准和规范如下:
- 人员标准:技术职级标准、绩效考核标准、候选人评估标准、干部评估标准
- 质量标准:代码质量标准、Code Review 标准、测试质量标准、线上质量标准
- 性能标准:服务端性能标准、客户端性能标准、前端性能标准
- 安全标准:代码安全标准、数据安全标准、线上安全标准
- 研发规范:代码风格规范、数据库设计规范、代码分干管理规范、代码提交规范、错误码规范
- 协同规范:架构规范、技术方案规范、技术文档规范、接口规范
在流程规范和协同之外,研发的效率和质量需要有一些基建来保障,如好用的框架,集成在框架中的静态代码分析,流畅且稳定的构建系统,靠谱的日志系统和监控系统,好用的链路跟踪系统等等。如果公司暂时没有这些,那么先看看业界有哪些,做一些选型后,把最合适的用起来。
你好,我是潘锦,超过 10 年的研发管理和技术架构经历,出过书,创过业,带过百人团队,也在腾讯,A 股上市公司呆过一些年头,现在在一家 C 轮的公司负责一些技术方面的管理工作。早年做过 NOI 和 ACM,对前端架构、跨端、后端架构、云原生、DevOps 等技术始终保持着浓厚的兴趣,平时喜欢读书、思考,终身学习实践者,欢迎一起交流学习。微信公众号:架构和远方,博客: www.phppan.com
除了眼前的苟且,还有架构与远方。
介绍创业路上的技术选型和架构、大型网站架构、高性能高可用可扩展架构实现,技术管理等相关话题,紧跟业界主流步伐。


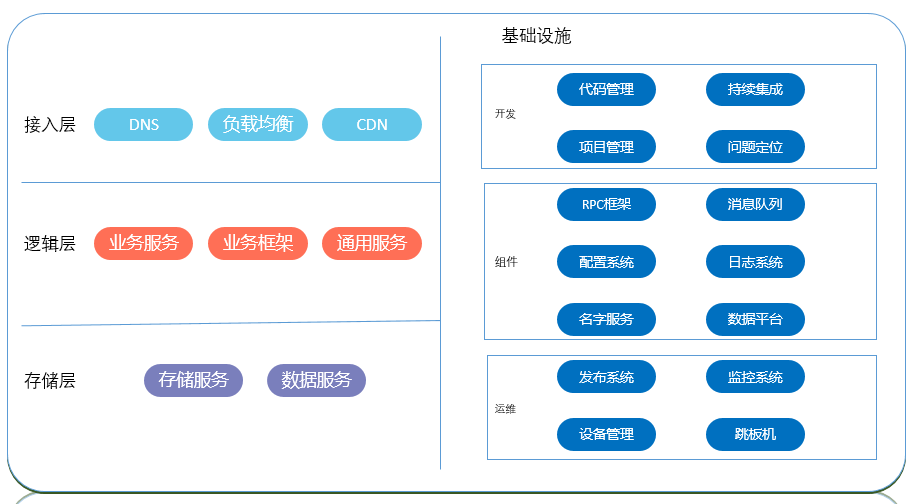
 有点眼晕,以上只是我们会用到的一些语言的合集,而且只是语言层面的一部分,就整个后台技术栈来说,这只是一个开始,从语言开始,还有很多很多的内容。今天要说的后台是大后台的概念,放在服务器上的东西都属于后台的东西,比如使用的框架,语言,数据库,服务,操作系统等等,整个后台技术栈我的理解包括4个层面的内容:
有点眼晕,以上只是我们会用到的一些语言的合集,而且只是语言层面的一部分,就整个后台技术栈来说,这只是一个开始,从语言开始,还有很多很多的内容。今天要说的后台是大后台的概念,放在服务器上的东西都属于后台的东西,比如使用的框架,语言,数据库,服务,操作系统等等,整个后台技术栈我的理解包括4个层面的内容: