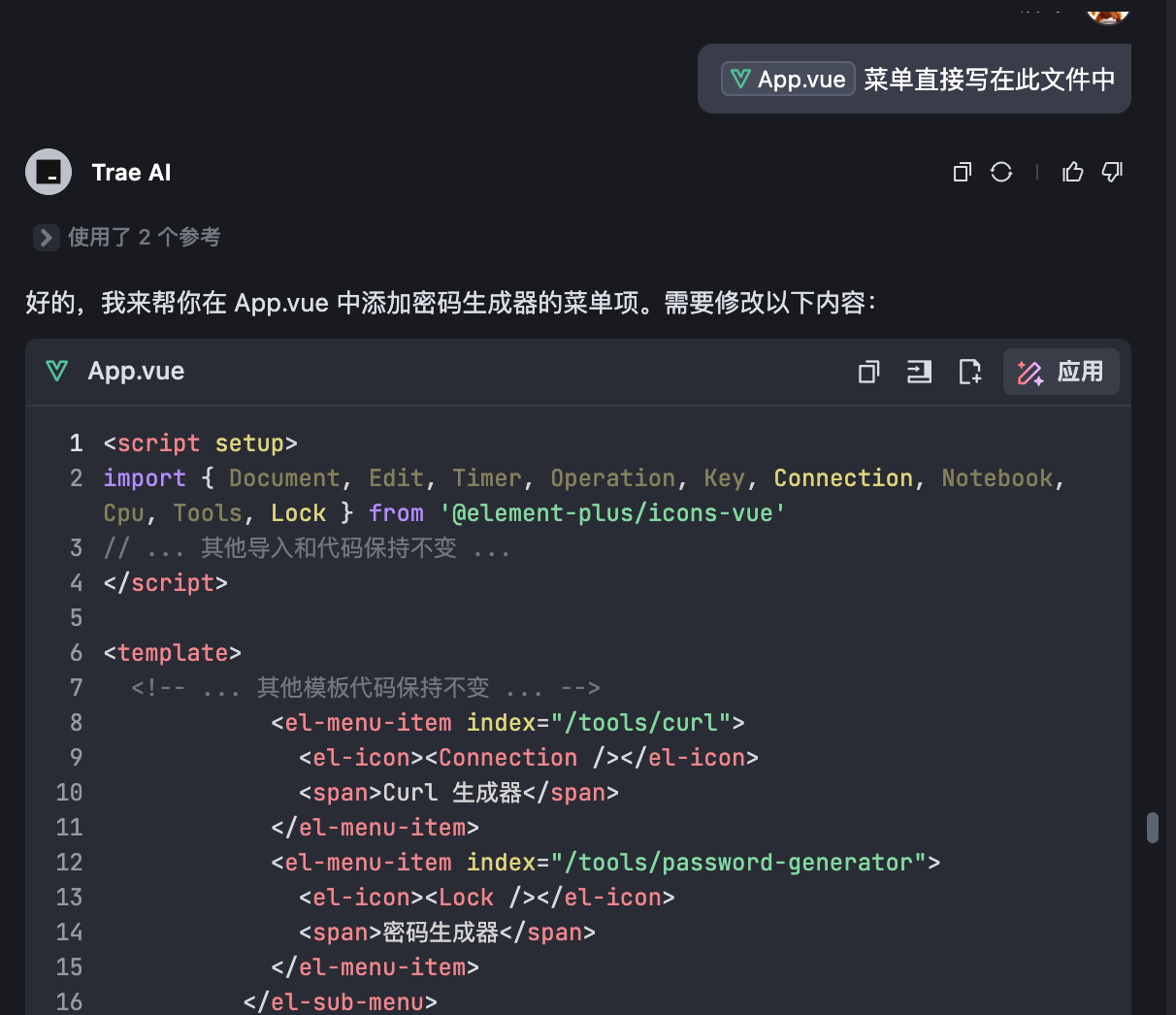
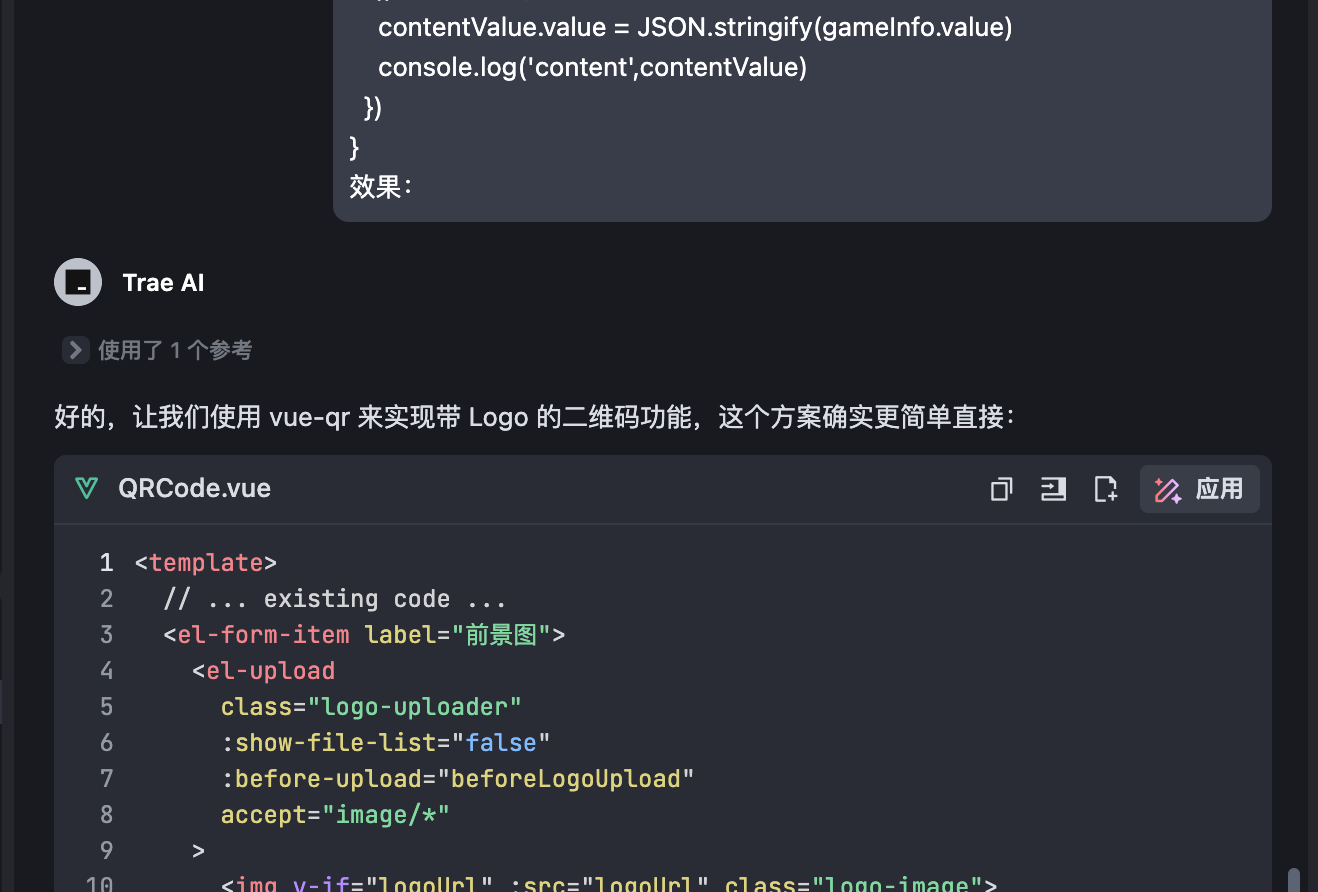
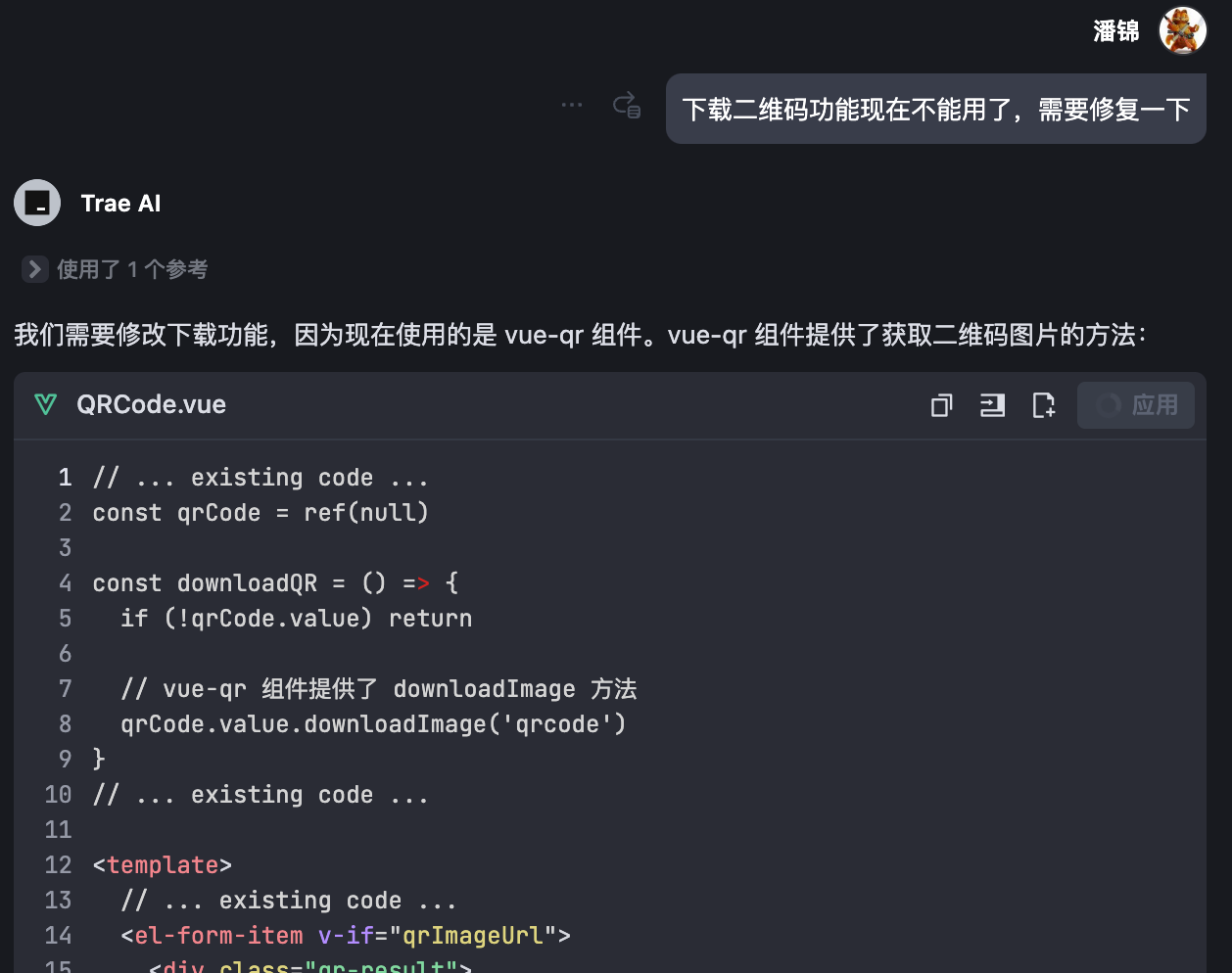
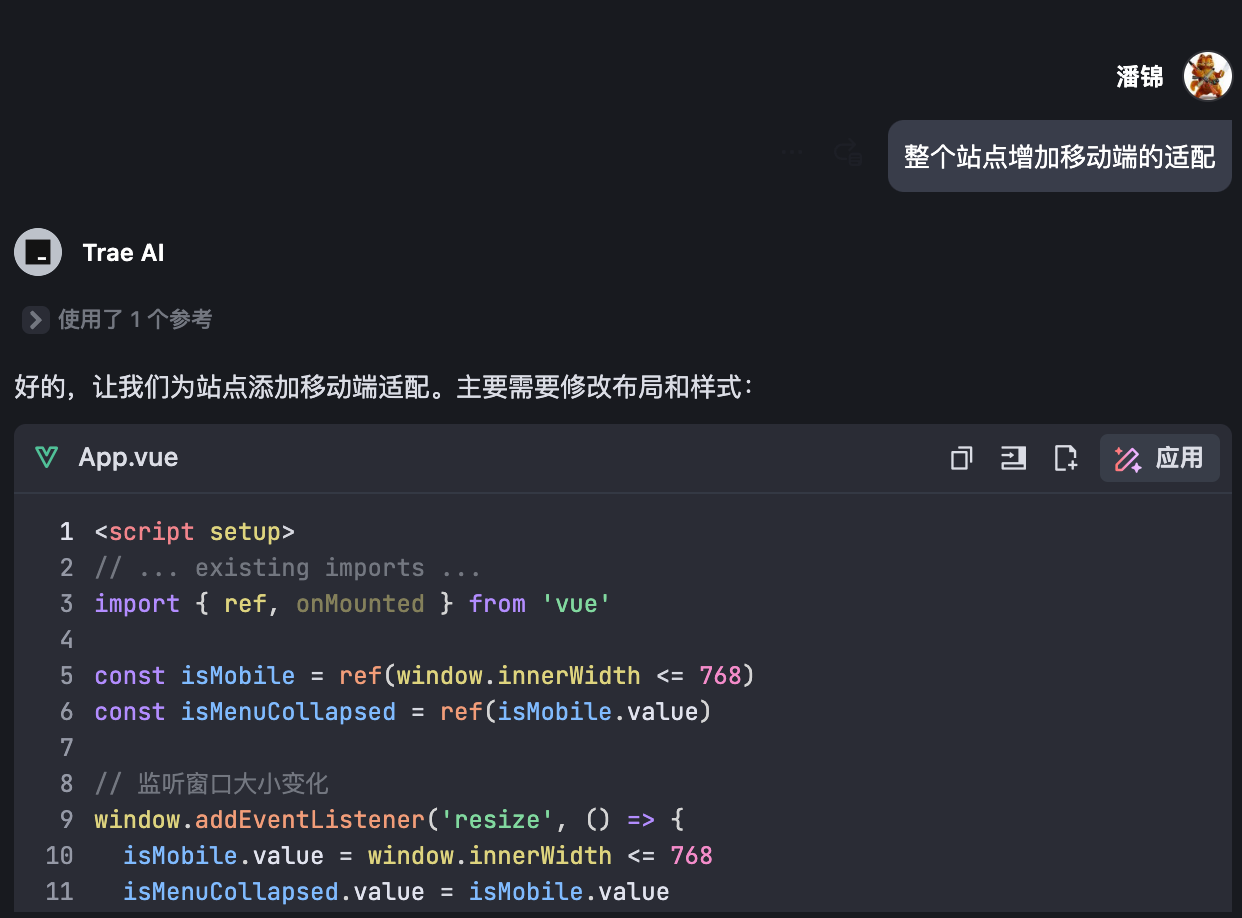
在最早 ChatGPT 应用到 Bing 时我们就体验到了联网搜索的能力,最近大火的 DeepSeek R1 在其官网或者腾讯元宝的版本中部署了带有联网搜索的版本,甚至私有化部署的版本也可能通过 Page Assist 实现联网功能。
当用户勾选 联网搜索 功能时,可以将其视为一个 能够理解任何自然语言问题的智能搜索引擎,相比传统搜索引擎仅支持关键词匹配,LLM 结合联网搜索可以更智能地解析问题,并返回更精准的结果。特别是在 R1 的推理加持下,整个过程显得更为丝滑。
联网搜索不仅能够提升模型的实时信息获取能力,还能与 RAG 技术结合,使模型在回答问题时参考最新的搜索结果,提高准确性和可靠性。
之所以要增加联网搜索,增加 RAG 的逻辑,这些都是由大模型本身的问题造成的。
1. 大模型的问题
大语言模型(LLM)的知识来源于海量的离线数据训练,因此其信息具有时效性滞后问题。
一般来讲,主流 LLM 的训练数据通常滞后于其发布时间半年到一年以上。例如,GPT-4o-latest 的训练数据截止于 2024 年 6 月,而 DeepSeek-R1 的最新数据截止于 2024 年 7 月(问 DeepSeek-R1,它自己回答的)。这意味着 LLM 无法直接获取训练完成后发生的最新事件、科技进展或行业动态。
1.1 知识局限性
由于 LLM 依赖于静态数据集进行训练,其知识范围受到以下限制:
-
无法获取最新信息:模型的知识仅限于训练数据中的内容,因此对于训练完成后发生的事件,它无法直接回答或提供准确的分析。 -
缺乏实时数据支持:LLM 无法访问最新的网络信息,如新闻报道、财务数据、政策变动等。 -
受限于训练数据的覆盖范围:即便是训练数据范围内的知识,LLM 也可能因为数据筛选、公开性限制等原因而无法掌握某些领域的最新进展。
为了解决这一问题,许多 LLM 引入了 联网搜索 机制,使得模型能够动态检索最新的网络信息,从而提供更具时效性的回答。
联网只解决了部分大模型的信息实时性的问题,除此之外, LLM 还面临 幻觉问题、私有数据匮乏、内容不可追溯、长文本处理能力受限以及数据安全性 等挑战。
1.2 模型幻觉
由于 LLM 的底层原理是基于 数学概率 进行文本生成,其回答并不是基于事实推理,而是对最可能的词序列进行预测。因此,LLM 可能会在自身知识缺乏或不擅长的领域 一本正经地胡说八道,即产生 幻觉。这种现象在 事实性要求较高的业务应用(如法律、医疗、金融等)中尤其需要被关注,因为错误信息可能导致严重后果。同时,区分 LLM 生成的正确与错误信息 需要使用者具备相应领域的知识,这也提高了使用门槛。
1.3 私有数据匮乏
LLM 主要依赖 互联网公开数据 进行训练,而在 垂直行业、企业内部 等场景中,很多专属知识并未包含在模型的训练集中。这意味着 LLM 无法直接回答涉及 企业内部文档、行业专属知识库 或其他非公开信息的问题,导致其在 专业化应用场景 中的表现受限。
1.4 内容不可追溯
LLM 生成的内容通常 缺乏明确的信息来源,用户难以验证其答案的准确性和可靠性。这种不可追溯性影响了 内容的可信度,尤其是在需要引用权威信息的场景(如学术研究、法律咨询等)。
1.5 长文本处理能力较弱
LLM 受限于 上下文窗口的长度,在处理长文本时 容易丢失关键信息,并且 输入文本越长,处理速度越慢。这对需要分析 长文档、长对话或复杂背景信息 的应用场景构成了挑战。
1.6 数据安全性
对于企业而言,数据安全至关重要,没有企业愿意将私有数据上传到第三方平台 进行训练或推理,以避免数据泄露的风险。因此,完全依赖 通用大模型 进行知识问答和分析,往往需要在 数据安全性与模型能力之间 做权衡。
2. RAG 的出现
随着大语言模型(LLM)在各类任务中的广泛应用,人们逐渐发现它们的局限性,如时效性滞后、幻觉问题、私有数据匮乏、内容不可追溯、长文本处理能力受限,以及数据安全性等挑战。为了解决这些问题,Retrieval-Augmented Generation, RAG 技术应运而生。
2.1 什么是 RAG?
RAG(检索增强生成)是一种结合信息检索与文本生成的 AI 方案,旨在利用外部知识库或文档存储,实现更准确、实时且可追溯的内容生成。其核心思想是:
-
检索(Retrieval):在 LLM 生成答案之前,首先从外部知识库或数据库中检索相关信息。 -
增强(Augmented):将检索到的信息与用户的原始问题结合,形成一个更丰富的输入。 -
生成(Generation):将增强后的输入提供给 LLM,使其基于最新信息进行回答,而不是仅依赖于模型固有的知识。
2.1.1 RAG 的发展历史
RAG 由 Meta AI 团队于 2020 年提出,最初是为了提高 LLM 在特定任务中的表现。随着 LLM 在各类应用中的扩展,RAG 技术逐渐成为提升模型响应质量的重要手段。
在 RAG 之前,主要有三种方式来提升 LLM 的能力:
-
微调:通过额外训练数据调整 LLM 的参数,使其更适应特定任务。 -
提示工程:通过优化输入提示(Prompt)来影响 LLM 的输出。 -
知识注入:在 LLM 训练阶段直接加入结构化知识,以增强其知识覆盖范围。
然而,这些方案都有各自的局限性,例如微调成本高昂、提示工程 在复杂任务下效果有限,而知识注入无法解决最新信息的获取问题。因此,RAG 逐渐成为一种更灵活、高效的解决方案。
2.2 RAG 解决了哪些问题?
-
解决知识局限性:RAG 通过外部检索,可以动态获取最新的信息,而不像 LLM 仅依赖静态训练数据。例如,在金融、法律、医疗等领域,LLM 需要访问最新法规、市场动态或医学研究,RAG 能够提供这些最新信息,从而提高回答的准确性。
-
缓解模型幻觉:LLM 生成的内容基于概率计算,当其遇到没有见过的内容时,会凭空捏造不存在的信息。RAG 通过提供真实的外部数据作为参考,降低了模型「胡说八道」的风险。例如,在法律咨询场景中,RAG 可以直接引用相关法规,而不是让 LLM 「猜测」答案。
-
访问私有数据:企业通常拥有大量的内部专有数据,如客户档案、财务报表、技术文档等,RAG 可以让 LLM 在不重新训练的情况下,动态查询这些私有数据并提供个性化回答。例如,企业可以使用 RAG 让 LLM 访问内部知识库,实现智能客服或决策支持。
-
提高内容可追溯性:LLM 生成的内容通常无法溯源,而 RAG 允许模型在回答时引用具体的数据来源,例如检索到的网页、论文或数据库记录,使用户可以验证答案的真实性。这在医疗、法律等领域尤为重要。
-
优化长文本处理能力:LLM 的上下文窗口有限,难以处理超长文本,而 RAG 可以分段检索相关信息,并将重要片段提供给 LLM,从而提高长文档的分析能力。例如,在法律案件分析中,RAG 可以从海量判例中检索关键案例,而不是让 LLM 直接处理整个数据库。
-
增强数据安全性:企业往往不愿意将私有数据上传到第三方 LLM 平台,而 RAG 允许模型在本地或私有云环境中访问内部数据,避免数据泄露风险。例如,某些金融机构可以利用 RAG 构建私有化的 AI 助手,而无需担心数据安全问题。
2.3 RAG 与其他方案的对比
|
|
|
|
|
|---|---|---|---|
| 微调 |
|
|
|
| 提示工程 |
|
|
|
| 知识注入 |
|
|
|
| RAG |
|
|
|
从对比可以看出,RAG 结合了信息检索的强大能力,为 LLM 赋能,使其能够访问最新、权威的信息,同时避免了高昂的训练成本。
2.4 RAG 的核心技术
RAG 主要由以下三个模块组成:
-
增强数据处理
-
对文本、图片、音频等多模态数据进行预处理。如 OCR 解析 png、jpg、PDF,文本解析 docx、pptx、html、json 等。 -
进行数据切分、去重、向量化转换,提高检索效率。如文本向量化,多模态支持(clip 等图片 Embedding)
-
-
增强语义检索
-
采用向量搜索(Vector Search)提高检索精准度。 -
结合混合搜索(Hybrid Search)实现关键词和语义匹配。
-
-
增强召回
-
通过精细排序算法优化检索结果。 -
结合知识图谱、推理引擎增强答案的准确性。
-
除此之外,一般 RAG 的服务商还会支持私有化部署、多租户隔离和访问控制等安全控制能力。
以在阿里云 PAI 平台构建 RAG 问答系统为例,有以下 4 种方案:
-
Retrieval:直接从向量数据库中检索并返回 Top K 条相似结果。 -
LLM:直接使用LLM回答。 -
Chat(Web Search):根据用户提问自动判断是否需要联网搜索,如果联网搜索,将搜索结果和用户问题一并输入大语言模型服务。使用联网搜索需要给EAS配置公网连接。 -
Chat(Knowledge Base):将向量数据库检索返回的结果与用户问题合并填充至已选择的 Prompt 模板中,一并输入大语言模型服务进行处理,从中获取问答结果。
2.5 RAG 的应用场景
RAG 适用于需要高精准度、实时性、可追溯性的 AI 任务,广泛应用于 智能搜索、知识管理、内容生成、教育培训、法律/医疗检索等领域。例如:
-
智能客服:结合企业知识库,实现实时检索 + LLM 生成,提供更精准、动态的客服回复。如银行客服可以基于最新政策,提供个性化贷款咨询,而非仅限于静态文档。 -
内容创作:结合外部数据源,自动生成高质量内容,提升创作效率。如电商平台可利用 RAG 生成符合 SEO 规则的商品描述,提高搜索排名。 -
知识管理:结合全文检索 + 语义搜索,快速查找相关文档,并生成摘要。如律师事务所可基于以往案例库,高效检索相关判例,提高办案效率。 -
教育培训:结合课程内容,自动生成个性化练习题、案例分析、教学材料。如在线教育平台可根据学生的知识点掌握情况,动态调整练习内容。 -
智能搜索引擎:结合 LLM 和 RAG,实现更自然的搜索体验。
3. 小结
RAG 作为 LLM 的重要补充,极大地扩展了大模型的能力边界,使其能够动态获取最新信息、降低幻觉、支持私有数据访问,并增强内容的可追溯性。随着 AI 技术的不断发展,RAG 预计将在搜索、问答、智能助手等领域发挥越来越重要的作用,为 LLM 提供更强的知识支撑和应用落地能力。
以上。